|
I am a forth-year PhD student at the Institute of Artificial Intelligence (IAI), University of Central Florida, advised by Dr. Chen Chen. From 2021 to 2022, I spent a wonderful period of time at GeWu Lab, working with Dr. Di Hu . Prior to that, I obtained my master's degree from Shanghai Jiao Tong University in 2021, working with Dr. Weiwei Cai. I obtained my bachelor's degree from Sichuan University. Beyond research, I regularly spend time on photography (see the gallery below), playing hold'em (low stakes smasher), music (Erhu, Level 10 certification), and a variety of sports (e.g., basketball, skateboarding). Email / Curriculum Vitae / X (Twitter) / 知乎 Zhihu / Google Scholar |

|
Open to Work! I am currently seeking full-time research opportunities in multimodal AI starting in 2026 and 2027.
|
My research focuses on multimodal AI—how we can build models that perceive, ground, and reason over long, complex procedures with different modalities involved. I develop benchmarks that stress advanced reasoning, grounding frameworks that align language with space-time, and representation learning methods that scale robustly.
|
|
[2026-04-30] SciVideoBench is accepted by ICML 2026! Thanks to all the collaborators for their dedication! [2026-04-30] One paper is accepted by ICML position 2026! Congrats to Shayda! [2026-03-12] VEBench is accepted by CVPR 2026 Findings Track! Stay tuned! [2026-01-25] AIR is accepted by ICLR 2026! Congrats to Yuanhao! [2025-10-20] SciVideoBench has been selected as the Best Benchmark Paper at the ICCV 2025 KnowledgeMR Workshop! [2025-10-10] SciVideoBench is available now on ArXiv! [2025-10-09] Thrill to announce the first ever scientific video reasoning benchmark SciVideoBench! [2025-03-23] I will be joining ByteDance this summer as a research scientist intern! [2025-02-26] Two papers accepted by CVPR 2025! Check GroundMoRe and Seq2Time! [2025-02-21] Invited talk at AXON about Video LLMs. [2025-01-25] OIS is accepted by ICLR 2025! Congrats to Bin! [2024-11-25] Seq2Time is available now on ArXiv! [2024-11-17] GroundMoRe is available now on ArXiv! [2024-06-25] GroundMoRe will be coming soon! [2024-05-27] I will be joining UII this summer as a research intern with Dr. Zhongpai Gao and Dr. Ziyan Wu. [2023-07-14] Two papers accepted by ICCV 2023! [2023-07-02] One paper accepted by IEEE TCSVT 2023! Congrats to Shoubin and Zhongying! [2023-03-13] One paper accepted by ICME 2023! Congrats to Wenke! [2022-03-09] I will be joining UCF this summer as a CS PhD student with Dr. Chen Chen. [2022-02-03] One paper accepted by CVPR 2022! Congrats to Xiaokang and Yake! |
|
* equal contribution |
|
|

|
Andong Deng, Taojiannan Yang, Shoubin Yu, Lincoln Spencer, Mohit Bansal, Chen Chen, Serena Yeung-Levy, and Xiaohan Wang ICML, 2026 Best Benchmark Paper@ICCV25-KnowledgeMR arxiv / project We introduce SciVideoBench, the first scientific video reasoning benchmark! |

|
Shayda Moezzi, Umer Saleem, Andong Deng, Chen Chen, and Sarah Ostadabbas ICML Position Track, 2026 arxiv (comming soon) Video LLMs must not ignore the pixel dynamics in plain sight: models and benchmarks must make spatiotemporal evidence unavoidable, and must fail when motion and state transitions are ignored or contradicted. |
|
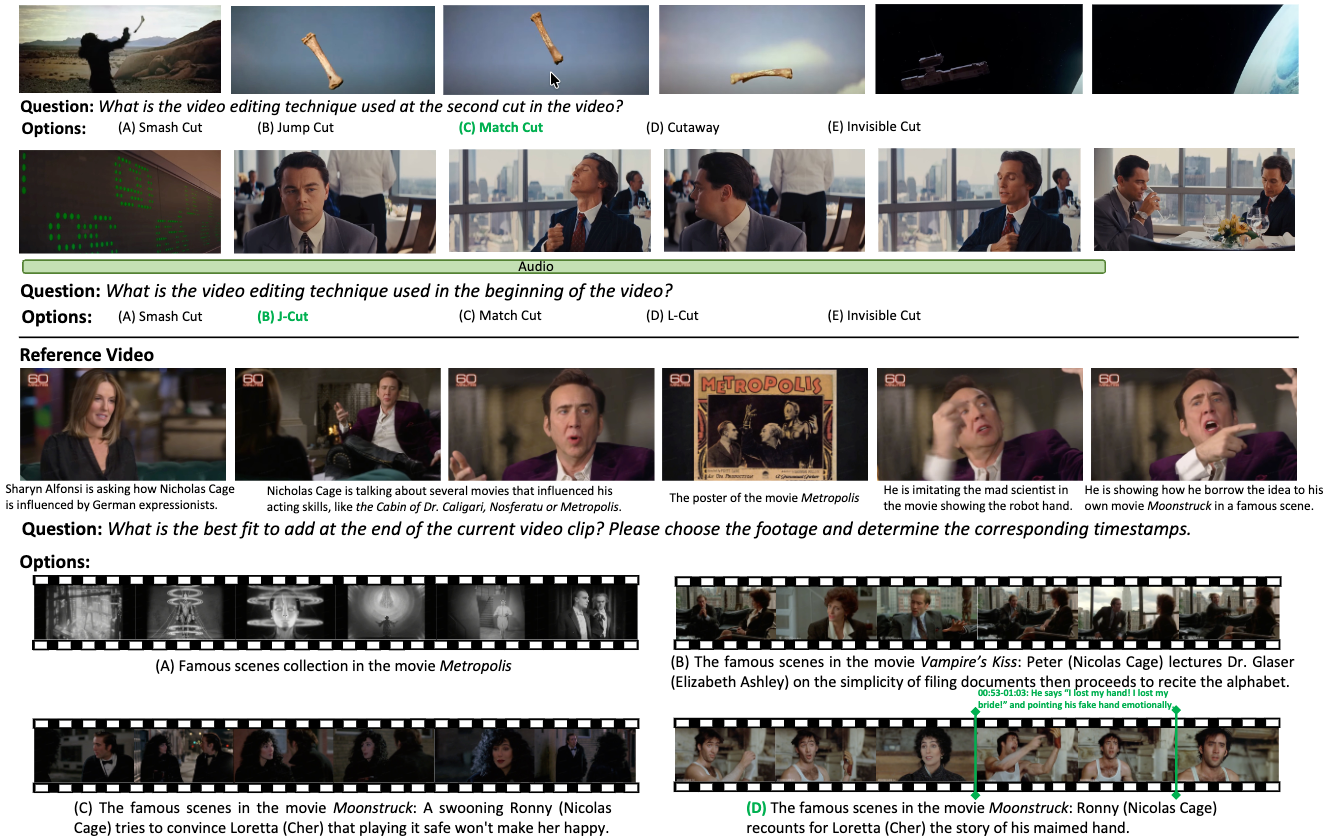
Andong Deng, Dawei Du, Zhenfang Chen, Wen Zhong, Fan Chen, Guang Chen, Chia-Wen Kuo, Longyin Wen, Chen Chen, and Sijie Zhu CVPR Findings, 2026 arxiv / project(coming soon) We introduce VEBench, the first comprehensive benchmark designed to evaluate both editing knowledge understanding and operational reasoning in realistic video editing scenarios |
|
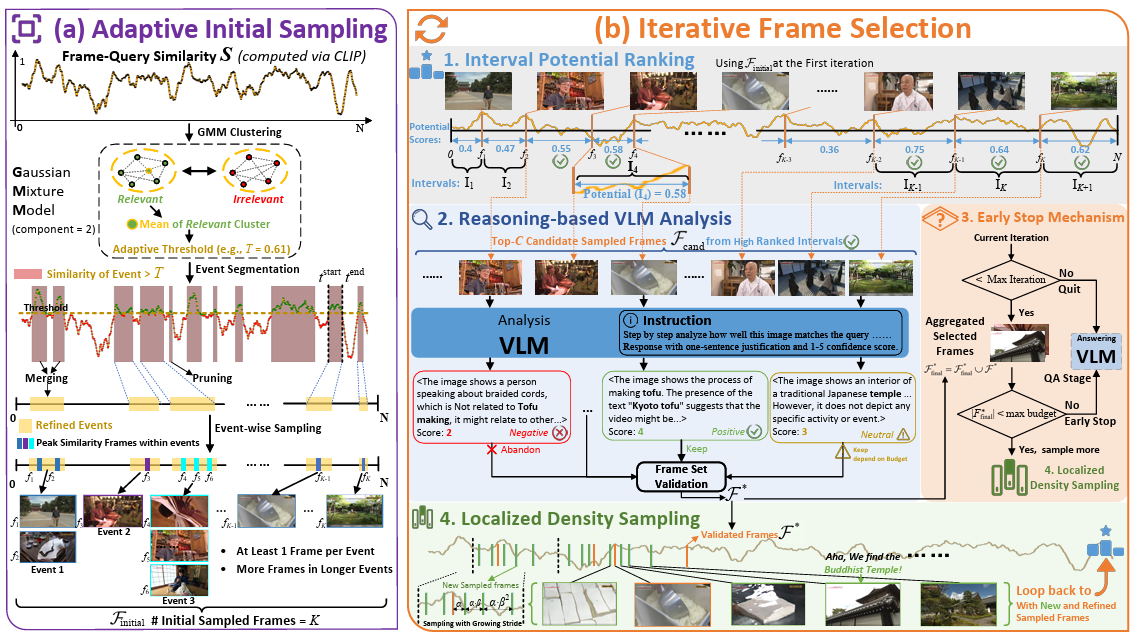
Yuanhao Zou, Shengji Jin, Andong Deng, Youpeng Zhao, Jun Wang, and Chen Chen ICLR, 2026 arxiv / project We introduce AIR, a training-free approach for Adaptive, Iterative, and Reasoning-based frame selection! |
|
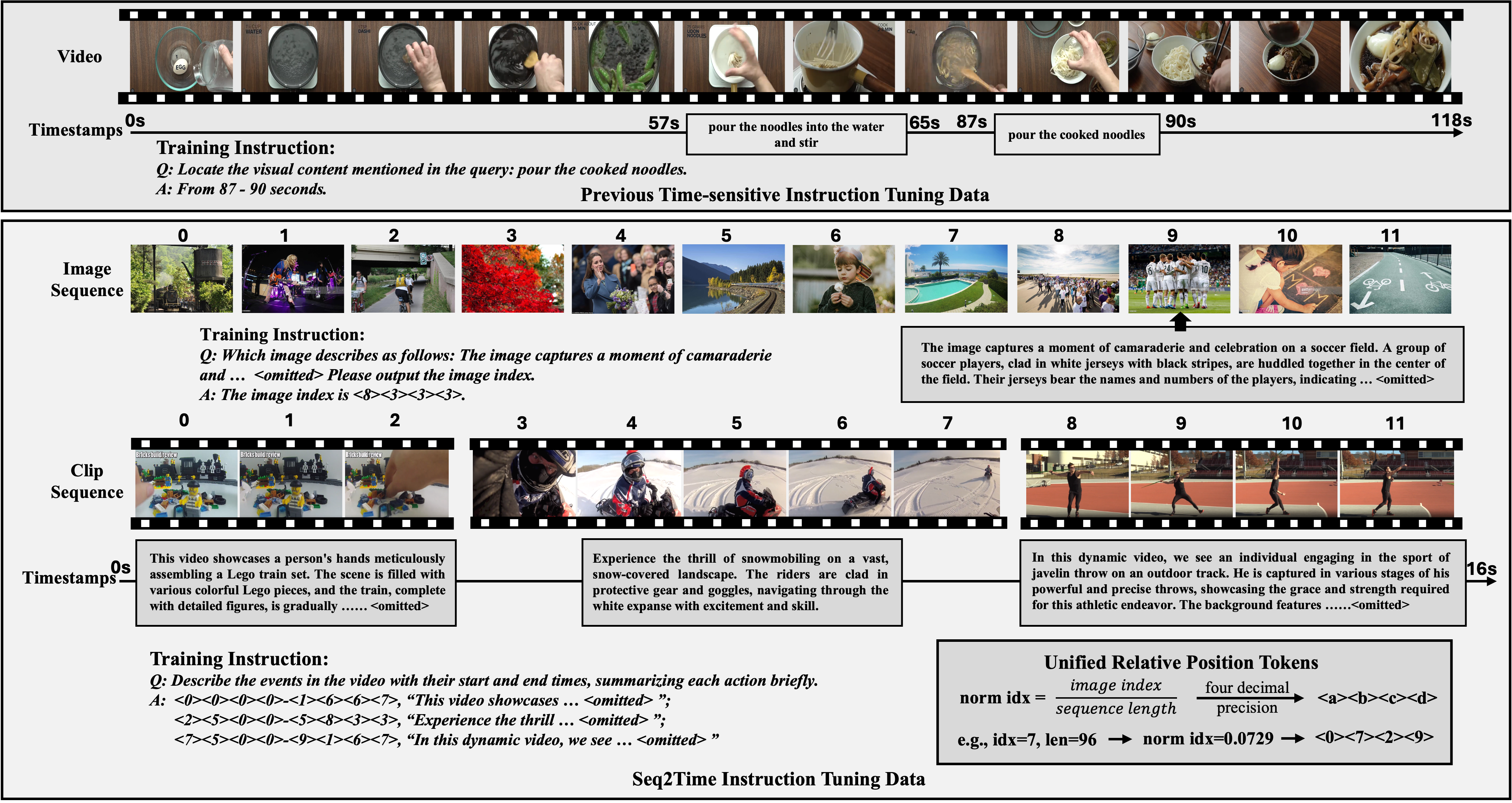
Andong Deng, Zhongpai Gao, Anwesa Choudhuri, Benjamin Planche, Meng Zheng, Bin Wang, Terrence Chen, Chen Chen, Ziyan Wu CVPR, 2025 arxiv / pdf We present Seq2Time, a data-oriented method to enhance the time perception ability of video LLMs. |
|
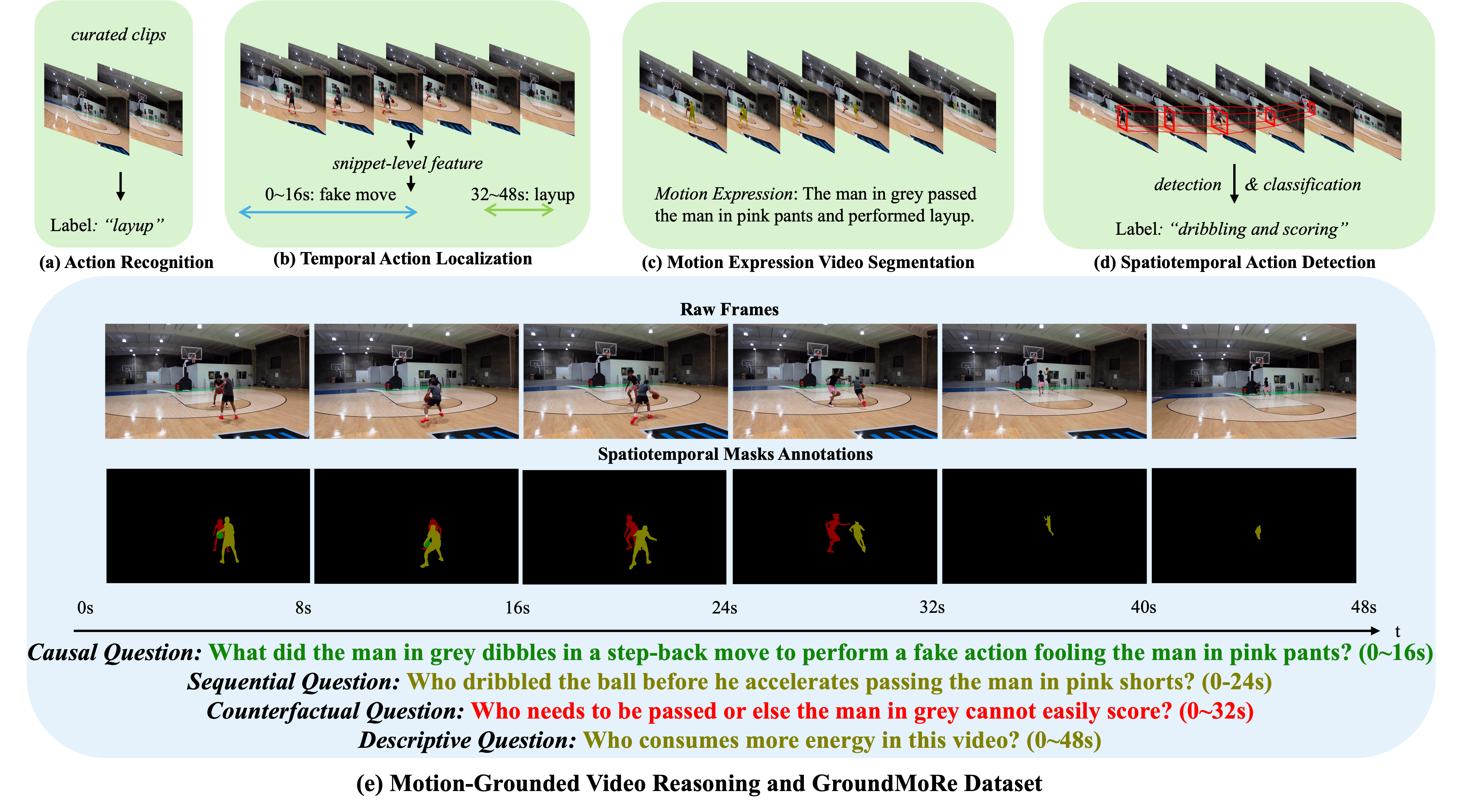
Andong Deng, Tongjia Chen, Shoubin Yu, Taojiannan Yang, Lincoln Spencer, Yapeng Tian, Ajmal Saeed Mian, Mohit Bansal and Chen Chen CVPR, 2025 arxiv / project We present GroundMoRe, a new benchmark for novel Motion-Grounded Video Reasoning; and MoRA, a video LLM that is able to reason and perceive motion at the pixel level. |

|
Haopeng Li, Andong Deng, Qiuhong Ke, Jun Liu, Hossein Rahmani, Yulan Guo, Bernt Schiele and Chen Chen International Journal of Computer Vision, 2026 arxiv / code In this paper, we introduce Sports-QA, the first dataset specifically designed for the sports-related VideoQA task. |

|
Bin Wang, Anwesa Choudhuri, Meng Zheng, Zhongpai Gao, Benjamin Planche, Andong Deng, Qin Liu, Terrence Chen, Ulas Bagci and Ziyan Wu. ICLR, 2025 arxiv / project We propose OIS: order-aware interactive segmentation, to explicitly integrate missing relative depth information into 2D interactive segmentation. |

|
Andong Deng*, Taojiannan Yang*, and Chen Chen ICCV, 2023 arxiv / code / CVF / Supp We introduce BEAR, a new BEnchmark on video Action Recognition. BEAR is a collection of 18 video datasets grouped into 5 categories, which covers a diverse set of real-world applications. |
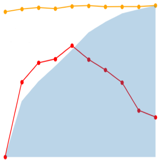
|
Andong Deng*, Xingjian Li*, Di Hu, Tianyang Wang, Haoyi Xiong and Chengzhong Xu ICCV, 2023 arxiv / CVF / Supp Inadequately pre-trained models often extract better features than fully pre-trained ones. And deep models tend to first learn spectral components corresponding to large singular values. |
|
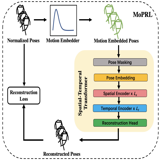
Shoubin Yu, Zhongying Zhao, Haoshu Fang, Andong Deng, Haisheng Su, Dongliang Wang, Weihao Gan, Cewu Lu and Wei Wu IEEE Transactions on Circuits and Systems for Video Technology, 2022 arxiv A motion prior distribution is utilized to construct the pose representation. MoPRL achieves the state-of-the-art performance by an average improvement of 4.7% AUC on several challenging datasets. |
|
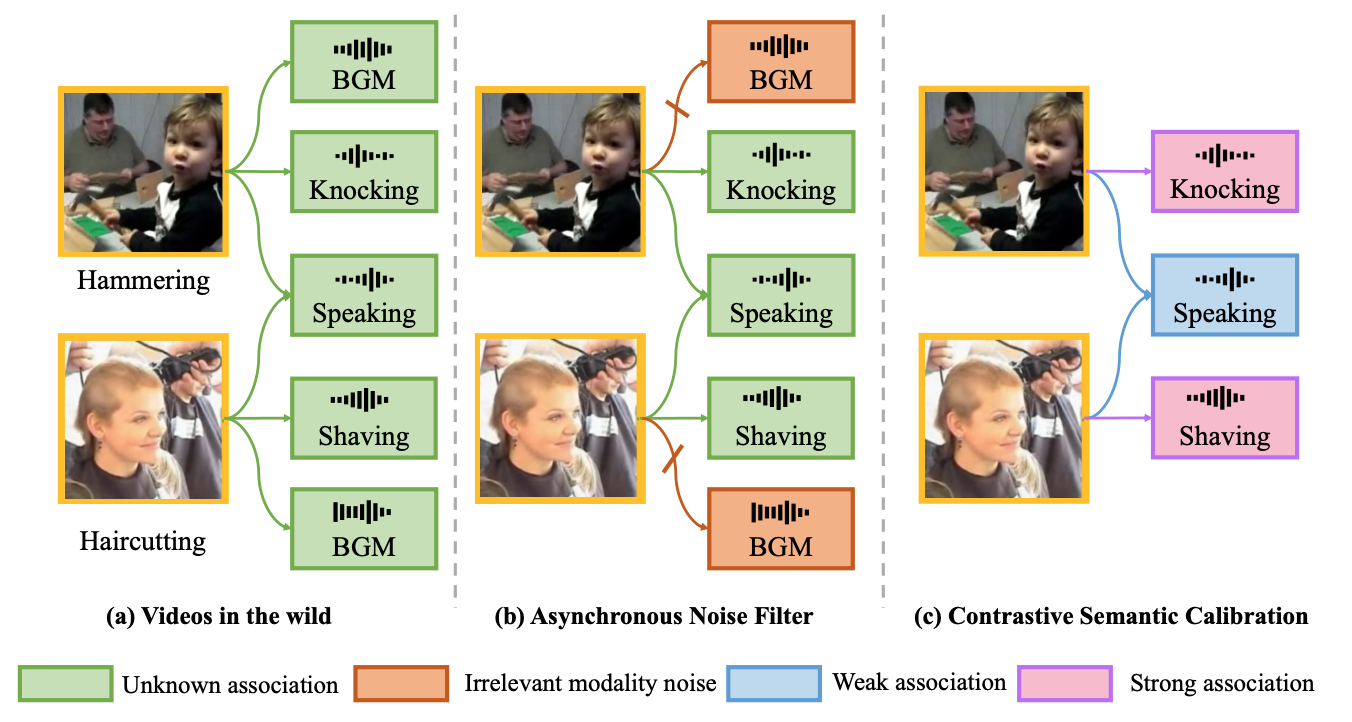
Wenke Xia, Xingjian Li, Andong Deng, Haoyi Xiong, Dejing Dou, and Di Hu ICME, 2023 arxiv We propose a Modality Noise Filter module to erase the irrelevant noise in teacher modality with cross-modal context and design a Contrastive Semantic Calibration module to adaptively distill useful knowledge for target modality, by referring to the differentiated sample-wise semantic correlation in a contrastive fashion. |
|
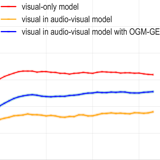
Xiaokang Peng*, Yake Wei*, Andong Deng, Dong Wang and Di Hu CVPR, 2022 (Oral Presentation) arxiv / CVF / code Modulate gradients of two modalities to adaptively balance the optimization process of multimodal learning. |
|
University of Central Florida
Ph.D.
Orlando, FL, USA
2022.08–Now
Shanghai Jiao Tong University
Master’s Degree
Shanghai, China
2018.09–2021.03
Sichuan University
Bachelor’s Degree
Chengdu, China
2013.09–2017.06
|
|
ByteDance Inc.
Research Scientist Intern
San Diego, CA, USA
2026.05–2026.08
ByteDance Inc.
Research Scientist Intern
San Jose, CA, USA
2025.05–2026.05
United Imaging Intelligence
Research Scientist Intern
Boston, MA, USA
2024.05–2024.11
Baidu Research, Big Data Lab
Research Intern
Beijing, China
2021.07–2022.03
GeWu-Lab
Research Collaborator
Beijing, China
2021.03–2022.06
|
|
Conference Reviewer: CVPR, ECCV, ICCV, ICML, ICLR, NeurIPS
Journal Reviewer: IEEE IoT, IEEE TNNLS, IJCV, IEEE TAPMI |
|
|





















Drag horizontally, use the arrow buttons, or press the left and right arrow keys to browse photos.
|
Updated: June 30th, 2026. |
Thanks Jon Barron for this amazing template. |